leetcode 01:哈希表
1. 两数之和
https://leetcode.cn/problems/two-sum/description/
给定一个整数数组 nums 和一个整数目标值 target,在数组中找出和为目标值 target 的两个整数,并返回它们的数组下标。
每种输入只会对应一个答案,且不能使用两次相同元素。
可以按任意顺序返回答案。
示例
输入: nums = [3,2,4], target = 6
输出: [1,2]
提示
- 只会存在一个有效答案
初始解
很久没有手撕代码了,磕磕绊绊的写了暴力解,还好测试是一遍过了。
跟以前写整个文件不一样,只写方法类的话可以直接 return 解,不再需要一层层 break 嵌套了。
vector<int> twoSum(vector<int>& nums, int target) {
int length = nums.size();
for (int i = 0; i < length; i++){
int value = target - nums[i];
for (int j = i + 1; j < length; j++){
if (value == nums[j]) {
return {i, j};
}
}
}
return {};
}学习哈希
了解后发现,其实在算法设计上学习的 hash table 就是哈希表,但之前只是学习基本原理,没有学到具体的使用实例。
哈希表在现在已经是一个很宽泛的概念,只要是将 KEY 和 VALUE 建立起映射关系的集合就可以叫哈希表。换而言之,之前在数据结构上学习的 ASCII 码数组也可以看作哈希表思想。
数组作哈希表
242. 有效的字母异位词
https://leetcode.cn/problems/valid-anagram/description/
给定两个字符串 s 和 t,编写一个函数来判断 t 是否是 s 的字母异位词。
示例
输入: s = “anagram”, t = “nagaram”
输出: true
解法
bool isAnagram(string s, string t) {
if (s.size() != t.size()) return false;
int table[26] = {0};
for (int i = 0; i < s.size(); i++){
table[s[i] - 'a']++;
}
for (int j = 0; j < t.size(); j++){
table[t[j] - 'a']--;
// 这个提前剪枝我没有想到,很巧妙地规避了再次遍历
if (table[t[j] - 'a'] < 0) return false;
}
return true;
}set 和 map 作哈希表
哈希表在 C++ 中通常就是指 set 和 map 容器了,但其实只有 unordered_set 和 unordered_map 是真正的哈希表实现。
set:
| 容器类型 | 底层实现 | 是否有序 | 数值重复 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|
set | 红黑树 | 有序 | 不允许 | ||
multiset | 红黑树 | 有序 | 允许 | ||
unordered_set | 哈希表 | 无序 | 不允许 |
map:
| 容器类型 | 底层实现 | 是否有序 | 数值重复 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|
map | 红黑树 | 有序 | 不允许 | ||
multimap | 红黑树 | 有序 | 允许 | ||
unordered_map | 哈希表 | 无序 | 不允许 |
红黑树是自平衡二叉搜索树,每次增删后自调整保持平衡;而哈希表则是用空间换取时间。两者底层原理不同,但对外的表现都是提供键值对的映射关系,所以都可以归为哈希法。
哈希表解法
使用哈希表前最重要的是确定题目的需求,以选用合适的容器类型。
- 对于这道题,首先排除数组的可能性,因为
nums[i]的范围太大,固定数组会浪费大量空间。 - 其次排除
set,因为题目最后要求返回数组下标,所以我们需要储存数值 + 下标,因此选择map。
粗糙解法
vector<int> twoSum(vector<int>& nums, int target) {
map<int, int> M; // num-slot
for (int i = 0; i < nums.size(); i++){
int val = target - nums[i];
if (!M.empty() && M.count(nums[i])) return {M[nums[i]], i};
M.insert({val, i});
}
return {};
}以上是我自己写的解法,AI 指出了三点不足:
map的优势在于有序存储,但这道题对此没有任何要求,应该改用unordered_map省时间。- C++ 标准库中对
count等方法的使用都是安全的,不需要额外检查。 - 使用了两次寻址(
M.count(nums[i])和M[nums[i]])略显冗余。
优化解法
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> M; // num-slot
for (int i = 0; i < nums.size(); i++){
// 存键值对,避免多次查询
auto it = M.find(nums[i]);
if (it != M.end()){
return {it->second, i};
}
int val = target - nums[i];
M.insert({val, i});
}
return {};
}49. 字母异位词分组
https://leetcode.cn/problems/group-anagrams/description/
给定一个字符串数组 strs,将字母异位词组合在一起。可以按任意顺序返回结果列表。
示例:
输入: strs = [“eat”,“tea”,“tan”,“ate”,“nat”,“bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
提示
- 仅包含小写字母
大致思路
在掌握哈希表后,题目的思路就清晰了,字母异位词的特征是字符组成相同,很容易想到将该特征作为 KEY 处理,既避免了新开数组,又达到了归类的目的。
粗糙解法
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> M;
for (string& S : strs){
string temp = S;
sort(S.begin(), S.end());
auto it = M.find(S);
if (it == M.end()){
M.insert({S, {temp}});
continue;
}
it->second.emplace_back(temp);
}
vector<vector<string>> ans;
for (auto it : M){
ans.emplace_back(it.second);
}
return ans;
}emplace_back 是 C++11 引入的一个方法,直接在容器末尾构造元素,避免了 push_back 的拷贝操作。
可改进点:
emplace_back(temp)已经包括了空则插入的前置判断。for (auto it : M)会在遍历时复制整个unordered_map。
优化解法
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> M;
for (string& S : strs){
string temp = S;
sort(S.begin(), S.end());
M[S].emplace_back(temp);
}
vector<vector<string>> ans;
for (auto& pair : M){
ans.emplace_back(pair.second);
}
return ans;
}另一个思路
也可以用字符频次作 KEY,优势是避免排序的时间复杂度,只用遍历一次即可拿到所需信息;劣势是空间复杂度偏高,且高度依赖题目提供的字符集大小。
for (string& S : strs){
string counts(26, 0);
for (char c : S){
counts[c - 'a']++;
}
M[counts].emplace_back(S);
}128. 最长连续序列
https://leetcode.cn/problems/longest-consecutive-sequence/description/
给定一个未排序的整数数组 nums,找出数字连续的最长序列,并返回其长度。
示例
输入: nums = [100,4,200,1,3,2]
输出: 4
解释: 最长连续序列是 [1, 2, 3, 4]。长度为 4。
提示
- 算法的时间复杂度可以优化至
大致思路
首先想到的解法就是利用 set 的有序和去重特性,将数组元素遍历插入后统计最长连续序列的长度。
粗糙解法
int longestConsecutive(vector<int>& nums) {
set<int> S;
for (int it : nums){
S.insert(it);
}
int max_length = 0;
int cur_length = 0;
int last_num = 0;
bool isFirst = true;
for (int key : S){
int cur_num = key;
if (isFirst || cur_num == (last_num + 1)){
isFirst = false;
last_num = cur_num;
cur_length++;
continue;
}
// 断增
max_length = max_length > cur_length ? max_length : cur_length;
last_num = cur_num;
cur_length = 1;
}
return max(max_length, cur_length);
}问题很明显: set 的插入和遍历都是 ,所以这里需要使用 的 unordered_set 。
我一开始也考虑过哈希表,但没想到怎么去解决哈希表元素无序的问题,后来才想起来直接使用 count 去找下一个元素就好了。
本质还是对 set 用法不够熟练。
优化解法
int longestConsecutive(vector<int>& nums) {
// 充分利用构造函数
unordered_set<int> S(nums.begin(), nums.end());
int max_length = 0;
// 哈希表元素不可修改,强制要求 const
for (const int& p : S){
int cur_num, cur_length = 0;
// 剪枝优化
if (!S.count(p - 1)){
cur_num = p;
cur_length = 1;
}
while (S.count(cur_num + 1)){
cur_num++;
cur_length++;
}
max_length = max(max_length, cur_length);
}
return max_length;
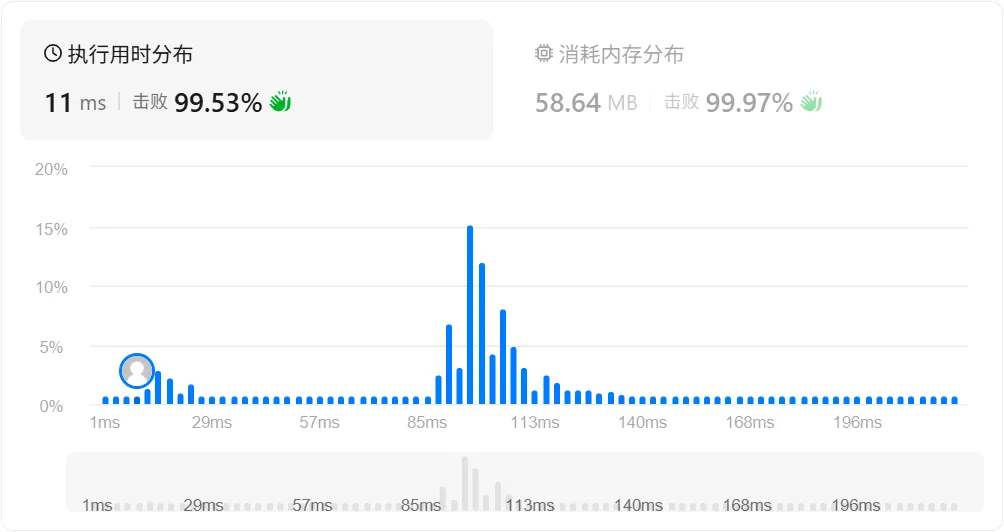
}利用构造函数、count 和剪枝优化后,代码的空间消耗降低,但时间消耗还是很差。
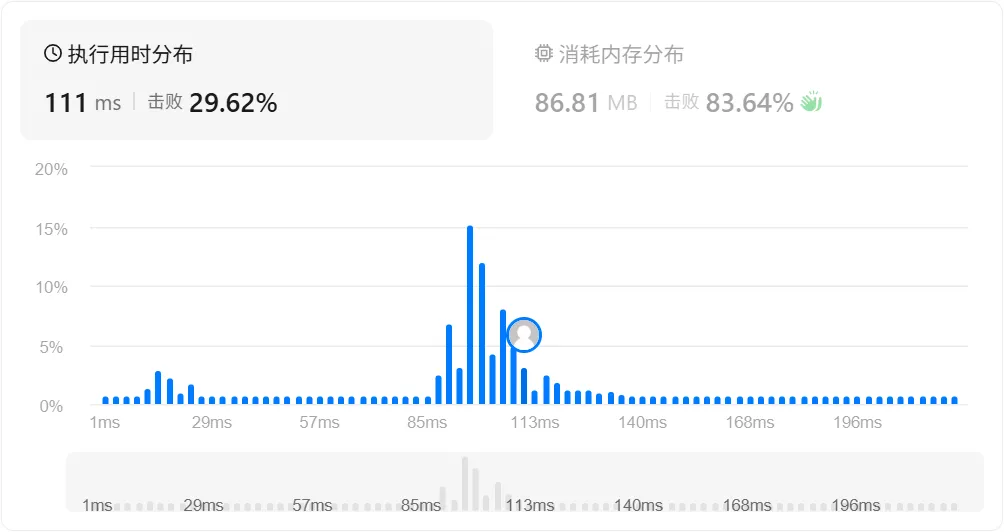
这是哈希表本身的劣势:
- 动态内存分配:
vector作为动态数组,在数据转移时无法预知大小,这会导致建立哈希表时会进行多次扩容和重哈希,这是很耗时的操作。 - 哈希函数计算: 虽然查表的理论时间复杂度是 ,但实际上每次函数的计算映射隐形开销也是不小的成本。
如果不使用哈希表而直接使用数组,效果会很好,但是一般情境下没有必要做到这种程度的优化。
数组解法
int longestConsecutive(vector<int>& nums) {
if (nums.empty()) return 0;
// 原址排序
sort(nums.begin(), nums.end());
int max_length = 1;
int cur_length = 1;
for (size_t i = 1; i < nums.size(); i++) {
// 重复元素跳过
if (nums[i] == nums[i - 1]) {
continue;
}
// 连续递增
if (nums[i] == nums[i - 1] + 1) {
cur_length++;
}
// 断开,结算长度并重置
else {
max_length = max_length > cur_length ? max_length : cur_length;
cur_length = 1;
}
}
return max(max_length, cur_length);
}